Using PostgREST for development, troubleshooting, and data endpoint
On Mon, 03 Mar 2025, by @lucasdicioccio, 2569 words, 0 code snippets, 8 links, 4images.
PostgREST is a service you can run to translate SQL tables in a Postgres
database into an HTTP API with REST semantics. For example, if you have a table
users with id, login, and created_at fields, you may map this table
onto a URL like https://example.org/users?id=eq.1234 returning a JSON array
of data rows. Among others, PostgREST is offered as a cornerstone service in
Supabase, proving that PostgREST is cool.
I’ve been recommending PostgREST throughout my career (even before it was cool), and needed to address several misconceptions. A brief explanation or elevator pitch like this may raise eyebrows, but it’s often too brief to alleviate concerns effectively. In contrast, dedicating time to address questions or showcase benefits is time consuming. Therefore, this article aims to provide a one-off thorough discussion of PostgREST’s strengths and weaknesses in an accessible and reusable format. Although some points specifically relate to PostgREST, many are applicable to other tools within the same family.
benefits
I list the key benefits of running PostgREST as a data access API.
PostgREST normalizes the API-query language
I believe the main advantage of PostgREST is that it standardizes an URL-based query language. HTTP URLs have been a part of the web landscape for some time and provide a practical way to identify specific pieces of information online. Here, PostgREST excels by offering a uniform method of querying data tables, which enhances discoverability and enables tooling to be built around the API. In contrast, naturally evolving APIs accumulate historical quirks and inconsistencies. With a result mixing query parameters, URL chunks, and result shapes. Support for data filters or rankers changes from one endpoint to another. For example, on a well-known site, you may be able to rank issues by their updated_at field but not code change requests. PostgREST URLs, while perhaps not aesthetically pleasing, at least provide uniformity and predictability.
HTTP is way more familiar than psql scripting
The most visible advantage of PostgREST is that exposing Postgres over an HTTP interface leverages a vast ecosystem of HTTP libraries and tools.
In a troubleshooting scenario, you simply need your browser to get started with
PostgREST. Then you can easily move to cURL, pipe the output through some
jq filters, and leverage other tools like xargs to perform actions in
batches. Replacing PostgREST+cURL with psql in JSON-output mode is
possible, but the experience is less familiar than cURL-ing an HTTP endpoint.
The operational constraints of PostgREST limits the query you may issue. However, based on my (non negligible) experience in troubleshooting, a significant portion of time is spent finding IDs and copying them into queries rather than crafting complex queries with non-trivial joins upfront. While there is still room for such non-trivial joins during one-off support, they are typically required in corrective actions once a problem has been well characterized (e.g., identifying all items that experienced a specific condition).
provides a 20/80 solution to dashboarding with PostgREST-Table
PostgREST offers a great dashboarding primitive brick.
This paragraph is self-promotion for PostgREST-Table,
which is motivated in the Help tab there. But the micro-summary is the fact
that you can get a Kibana-like experience with just Postgres+PostgREST and
minimal configuration. No need to export your data into yet-another data-store
and monitor these data export jobs when you can directly observe your Postgres
tables. Overall, you get 80% of the benefit for 20% of the cost (which I refer
to as 20/80 problems or solutions in the rest of the article) and
significantly less moving parts than other dashboarding approaches.
When processing jobs need to go over a set of data, we can generally create a
dashboard with a simple view to count items that have been processed and those
that have not. And with only that you can make an explorable chart to see what
data still needs processing.
provides a 20/80 solution to data-sink services
Another use-case is for situations where you want a data sink. For instance, to collect continuation-integration reports, web-analytics reports, or a shout-box. This website web-analytics is actually made with PostgREST: a write-only endpoint receives (untracked across pages) datums from an AJAX-POST after the page is initialized or when some click occurs. With only a bit of SQL-configuration and PostgREST, maybe a token-generation once, you get a nice API endpoint to just store a set of data items. Do not expect to get the scale and size of an S3 bucket but you can definitely imagine it as one. Here again, you get a solution covering a large scope for at a low complexity budget.
For instance, I’m planning to add data-sink for comments and “like buttons”. In the meantime you can click the following button, which should be enough to let me know:
configuring PostgREST is a forcing function to configure your Postgres
The number one risk of running PostgREST is a data disaster. Wait, take this back, data-disasters are risk which exist from just having a database. Data disasters are plenty in traditional web-applications. Thus, before exposing your SQL tables onto the web you need to pay attention to security. Strenghtening PostgREST is a required technical step and such technical step is not much different from doing the same in your backend services.
I think that security is the second most frequent objection engineers have to tools like PostgREST. I think this objection is rooted in a lack of familiarity with the role/grant system in Postgres. Learning the Postgres-role system will benefit your whole system in general. Indeed, configuring PostgREST access rights is done at the database level. In other words: when strenghtening PostgREST you are, in fact, strenghtening Postgres. Configuring PostgREST acts as a forcing function here.
I’ll discuss suggested setups later in the article. For now, let’s illustrate
with a simple example. For instance, if you have a data-sink table from the
previous paragraph, you may have some id serial primary key field, however
configuring an endpoint over PostgREST will force you to think “should
API-users be able to control the id field when inserting data? of course not”
and thus you’ll be modifying the GRANT so that the Postgres role for the data
collection can only write to the limited number of fields. Did you know that
Postgres would let you configure grants up to the column level? I did not until
I configured some PostgRESTs.
non-limitations
This section discusses frequent objections (beside those already discussed in the Benefits section).
API-to-schema coupling
The most frequent argument against using something like PostgREST is that it is a bad-practice to couple an API with a data-schema. I think this argument is a form of lazy thinking (in general, the whole epistemic field of defining good/bad practices is tiresome, I live for trade-offs). For sure, there is coupling between the REST-schema and the table-schema, in fact, the coupling is exactly we ask PostgREST to provide: a 20/80 solution.
In some use cases, coupling is what we need, for instance, when troubleshooting a data problem for a customer. While troubleshooting, we need to compare the real data to processed responses so that we can form an opinion on whether the data is wrong or the code is wrong.
In the more general case, you are fine with some amount of coupling. Indeed, schema changes are annoying even for traditional services, thus backward-incompatible schema changes are rare anyway. The key architectural choice whether to live with some coupling or not is to properly identify your level of control over API-clients (i.e., doing a REST api for a mobile app vs. a REST api for a B2B app vs. a REST api to support third-party connectors).
In the use case where you are afraid to break backward compatibility, you still can add indirections. In SQL, chiefly, you can decide to only expose tables with rarely-varying shapes, exposing only SQL views, or table-returning functions. You can even expose different tables with different “service-level guarantees”.
In PostgREST you can get by with the following rule of thumb: if the Postgres schema changes, I risk some incompatibility otherwise, the change is compatible. Backward incompatibility breakages are much harder to identify in traditional backend-servers (and testing backward compatibility requires extra tooling and significant investments in QA).
The rollout of an incompatible change is not much different for a traditional service than from PostgREST: either accept a migration downtime or add a new endpoint, then move clients, and dispose of the old endpoint.
Finally, I would rarely propose to use PostgREST alone. I would recommend to limit PostgREST to data endpoints rather than endpoints pertaining to user configurations or with many round-trips. When running PostgREST in tandem with other endpoints, the exact setup I suggest depends on the type of customer you face and how much control you can exert on API clients, again there is nothing specific or especially different between PostgREST and more traditional backends.
limitations
I’m a honest-to-god scientist. Thus I am not doing marketing talk just to do marketing talk here. Although I’ve been using PostgREST, although Supabase uses PostgREST. This marvelous tool has some limitations. They may become deal-breakers for specific applications as some limitations have no easy workarounds.
pagination is sometimes limiting
Traditional and historical SQL database are not perfectly-suited to a world where you want to process millions of rows. PostgREST inherits some of these limitations, for instance, there is a maximum number of rows a single query can return. For performance reasons, REST APIs leverage pagination. However a problem with pagination is that the result set being paginated may be shuffled between two API calls (leading to duplicated predicate evaluation on the backend and possibly incomplete/overlapping enumerations).
I would welcome some streaming on top of cursors.
embeddings are nice but sometimes limiting
The embedding mechanism allows to follow SQL-foreign keys to embed resource.
For instance, you can ask in one go for the blog-posts of users if blog_posts
references users via something like author_id.
I have a few bones to pick with embeddings:
- cross-schema joins are not supported (in case you use SQL schemas)
- embeddings end up complexifying URLs, this is a price I’m ok to pay and I do not think it should become a blocker to anyone, but it’s good to know that URLs become more challenging to guess
- embedding follows foreign-keys in a strange way
- disambiguation is needed when multiple join clause would match, i think one key aspect here is that the embedding follows table names rather than column names (i.e.,
users.postsneeds disambiguation when we mean “author_id” or “reviewer_id”); ther rules are not really intuitive - non-foreign-key joins are, alas, not supported; I reckon they would require significant changes to the URL-structure but it would be nice to be able to decide what tables to join and on which predicate (e.g., if a table has a “key but without foreign-key constraint for performance reasons”, or when we want to make non-trivial joins or filtering joins)
- disambiguation is needed when multiple join clause would match, i think one key aspect here is that the embedding follows table names rather than column names (i.e.,
If non-trivial embeddings are rare but needed, you can work around using functions or views. If your use case will lead you to primarily make a lot of embeddings, you may look into something like Hasura. The setup cost is much harder, the preferred exposure mechanism is GraphQL, which comes with its own extra trade-off, but overall you’d get the “right tool for the job”.
sometimes you want more
PostgREST is a 20/80 solution, meaning that for 20% of the effort, you can
address 80% of use cases. In the remaining use cases, some feel reachable to
something like PostgREST. One thing I miss is to expose directly some
parameterized .sql snippets. The equivalent today is to define functions.
However defining functions is more work for users and sometimes unavailable to
some users. Indeed, to define function you need special grants, whereas for
most deployments, PostgREST should run without the right to make changes to the
SQL structure. If you are in need of such a tool, I think I would recommend
SQLPage. Although I’ve not used SQLPage myself,
everything I’ve read about the tool is promising. The difference between
enabling .sql snippets and requiring a migration of said snippets first is
subtle but it would do wonders to become a 20/90 solution rather than a 35/90
solution.
Now that we understand better the benefits and limitations of PostgREST. Let’s envision how to use and setup PostgREST depending on your particular use case.
proposed use cases and architectures
The underlying theme is to reflect about the control boundaries. Who will be a user of PostgREST API? what do they need?
We proposes four deployment modes:
- in development
- in casual support
- in prod, mono-tenant
- in prod, multi-tenants
In each of these deployment we assume a simplistic Postgres deployment. Which consists of a single Postgres instance. But you could totally work on more complicated setups such as connecting to a read-replica or connecting to some other Postgres-compatible database such as CockroachDB.
deployment patterns
in dev
Corresponds to situations where you are developing an application. Your application Postgres database, your PostgREST and your development tools all run locally and do not expose themselves to the internet.
The setup is depicted below.
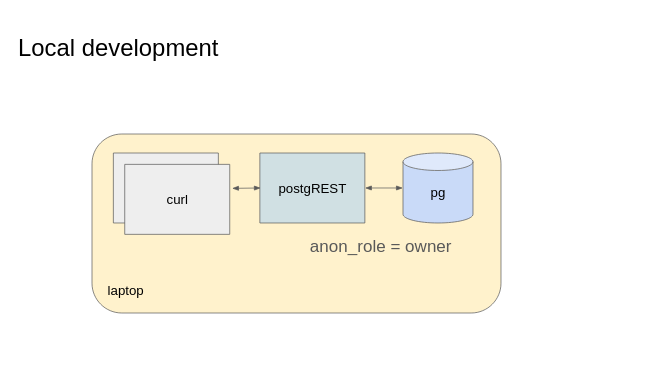
Here the deployment is pretty inconsequential. Data is not private. Typically it is fine to re-use the same role (i.e., one connection string to configure) across your backend tools, including PostgREST. No need to configure a dedicated user or a JWT signing key: you rely on preventing PostgREST api calls from malicious machines.
in casual support
I refer to casual support, the situations where you need to read data in the
table, likely revealing customer information. Thus ultimately you will be
presenting user-data on your screen, which requires some extra care. This mode
is not different from running psql or DBeaver on the
production database.
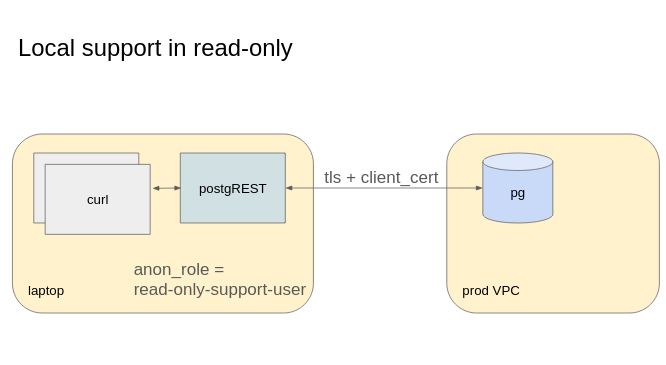
You may want to run PostgREST locally and temporarily. In that case, make sure that your connection from your laptop to production is covered by TLS. The best is to use TLS and client certificates for authenticating your laptop and cyphering the connection between PostgREST and your database.
in prod (mono-tenant applications)
This situation occurs when some data is somewhat similar and each user as a same view on the data. For instance, you provide a curated news service: each user may have a different selection of news feeds but any user may access any feed. Serving the news feed over PostgREST is likely enough and you may only need to check whether a user is authentified or not.
In this situation:
- configure two users for PostgREST, an anon role and an authentified (read-only) role
- only grant select on the news feed to the authentified role
- a “traditional backend” provides users with billing and configurations
- (optionally) place both the backend and PostgREST behind an L5-proxy (or routing load-balancer)
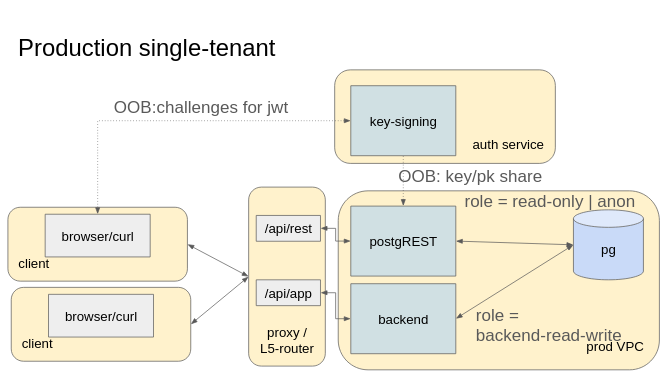
Summarizing, the Postgres roles I’d recommend would be:
- db-owner user
newsfeed_owner: a user that applies migrations - read-only user for PostgREST
newsfeed_authentified_ro: can only select feed items - login-switch-only user for PostgREST: a role that can only impersonate
newsfeed_authentified_ro, it has no grant to select any table, except if a table is fully-public - a (set of) role for the backend like
newsfeed_api_backend_rw
You’ll also need a key and a JWT-signing endpoint such that clients can present a JWT to PostgREST. Typically, you would use the same token as for the backend such that the clients do not have to pick based on the API routes. Using bearer tokens, all the signing and key sharing occurs out of band compared to API calls.
in prod (multi-tenant applications)
This situation occurs when you want each user to have a access to a subset of data. That is, when the data is segmented across user. In that situation, you should likely be using row-level security.
The only difference with the mono-tenant applications integration schema above is the fact that the authenticated user now has read-write access to some tables and these tables should be protected using row-level security based on a claim in the JWT. The rest of the setup stays the same.
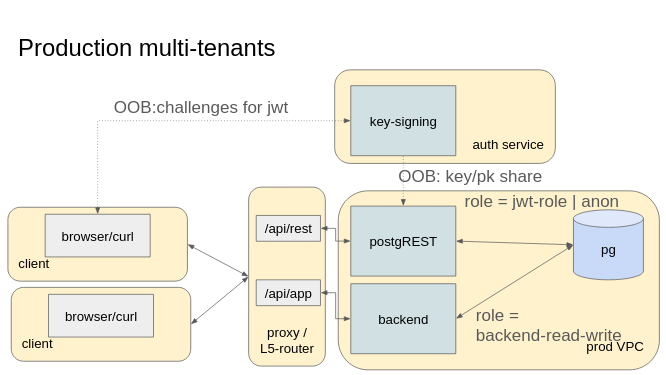
On thing I’ve never used and feel unsure about: using one PG role per end-user. Indeed, the extra burden of synchronizing Postgres users roles and ACLs with your own application user system seems too much for me. For most of the application I envision, the combination of row-level security with the scape-goat to use a traditional backend as work around already solves most of the problems.
summary
PostgREST is a good 20/80 solution to many user cases. PostgREST has many benefits, from normalizing and industrializing some recurring patterns in REST and data-products, to forcing you to think about Postgres security upfront. By providing a well-rounded set of features in a single binary, you can augment your development and troubleshooting experience, or offer users with data endpoints, without spending much of your complexity budget on extra infrastructure. Overall you should consider #postgrest and if you do, please give me a shout and try PostgREST-Table.