How I write PureScript web-apps: Part-III
On Wed, 12 Feb 2025, by @lucasdicioccio, 2499 words, 6 code snippets, 17 links, 1images.
This article dives straight into discussing cross-cutting concerns. If you need additional context or wish to grasp the core state management, rendering, and event-handling layout I recommend for a Halogen application, please read the first article. In this article, we will also refer to contravariant Tracing, a topic I cover thoroughly in the second article.
parameters and configuration
Some JavaScript frameworks like Next will consider configuration to be a regular JS-module known at “compilation” (nb: the configuration itself can be dynamic, hence offseting the problem of actually picking config values), which means you’ll need different compilations for different environments.
For the applications on this blog, I prefer to maintain a simplistic build
chain: I compile a single artifact while I’m editing new articles on my blog.
When I’m publishing articles for you, adorable reader, I can re-use the same
.js file that I used and tested locally. An extra use case which is specific
to blogging, sometimes I even want to include a script multiple times with
different configurations on a single page. This setup means that the script I
ship has an initialization phase to lookup the configuration in its
environment (example: Halogen-Echarts demo).
This way of configuration applications is no different from a process reads
commmand line arguments and environment variables, except that for a JavaScript
module, the environment generally is a web-page or a browser extension.
Implementation-wise, there are no specific challenges. I prefer to locate
configuration directly in the <script> tag using HTML data attributes .
For instance, an application that needs an API-key and an API endpoint would look like
<script
scr="/js/my-app.js"
data-my-app--api-endpoint="https://example.com/"
data-my-app--api-key="0xdeadb33f"
>whereas while developing locally I would use a different configuration
<script
scr="/js/my-app.js"
data-my-app--api-endpoint="http://localhost:3000/"
data-my-app--api-key="dummy"
>Now you can object that the difference is small as the .html in development
and the .html in production are different. However there are a host of ways
to parametrize the .html source for web applications. The decision to split
the configuration has a some advantage when troubleshooting a bug. Indeed, you
can retrieving the .js actually served to customers and you do not need to
alter it to override the configuration: the application knows how to do that.
In PureScript, querying the environment is not too complicated and types will
guide you. You just need to use Web.DOM.Element.getAttribute and
Web.HTML.HTMLScriptElement.currentScript. Then you build your configuration
object in an Applicative style and you are done.
I recommend you define a TagInsertionConfig (name can vary of course) as a
record of Maybe String, however you can directly map them if you want to
split strings, parse integers in one fell swoop.
import Web.DOM.Element (getAttribute)
import Web.HTML.Window as Window
import Web.HTML.Window (Window)
import Web.HTML.HTMLScriptElement as HTMLScript
type TagInsertionConfig =
{ endpoint :: Maybe String
, apiKey :: Maybe String
}
readConfig :: Window -> Effect TagInsertionConfig
readConfig win = do
script <- currentScript =<< Window.document win
traverse go script
where
go script = do
let elem = HTMLScript.toElement script
TagInsertionConfig
<$> getAttribute "data-my-app--api-endpoint" elem
<*> getAttribute "data-my-app--api-key" elem
main :: Effect Unit
main = do
w <- window
config <- readConfig w
doStuffWithConfig configIn large applications, you will also need a distinguished RuntimeParams
object with extra environment objects like a Tracer configured (as described in
the TagInsertionConfig above) to send application digests to your main server
etc. Another place where you can likely want to read information is using the
Windows “location” either by hand for simple situations (e.g., simply branch on
a query parameter), or reusing some pre-existing routing
library.
Finally, there is no reason why you cannot have a Configuration module
generated or selected in your build pipelines, allowing for diverse approaches
to be combined.
storing and restoring state
If you have managed to play with PostgREST-Table or Prometheus-Monitor you’ll notice that configurations persist across refresh.
The implementation is simple although a tad verbose:
- define a “stored type”, which holds a storable-representation of the configuration you want to persist, this
StoredStatemust be part of the Page’s component Input (or Props) - define encoder/decoders (most likely JSON objects)
- define a Tracer that will save the application state upon encoutering some particular Events, the most simple way to do so likely is to have some Trace defined as
TraceSaveState Statein your Page component - define a function that will load the stored state (if any)
- if you want to store locally in the browser, the object you want is Web.HTML.Window.localStorage
- pass the Tracer to your Page component
Forcing oneself to separate the stored configuration object from the application State “core object” is a good practice to simplify the forward compatibility of stored state acrosse upgrades of the application.
Another benefit of this approach is that one can easily change the storage location, for instance to store objects in a SAAS. You can also change the location (e.g., the local-storage key) based on the application RuntimeParams.
The only drawback of using a Tracer object to perform the store Effect is that it becomes more difficult for the core application to know which state is effectively stored, however it is easy to start decoupled and add coupling later, whereas the converse is rarely true.
simulating inputs for tutorials
If you have read my Project-Scope mini-app you’ve noticed the application can be driven in two ways:
- by playing around
- by pressing a button in the “Tutorial” section
The good news is that there is nothing especially hard in Halogen to simulate inputs: you just need some “next” button that triggers.
The boundary is difficult
type and API utilities
PureScript descends from a family of programming languages preferring to use
rich data-types to encode the state of applications. In a web-setting, where
network interaction abund, two key data-types are useful and you will likely
need some version of it: Remote data and Historical data.
Remote data
When you need to request some information (e.g., fetching the latest news on the blog). You want to distinguish a few situations: the data has not been requested, the data is being loaded, and, we could not the data at all. I use a Remote type directly-copied from Kris Jenkin’s Remote-data for Elm.
The constructors I use, that is, the states I want to capture, are the same in Kris’ blog post:
data Remote a
= Uninitialized
| Loading
| Errored String
| Got aThe surprising thing for a React developer here may be that we decouple any
API-calls from the representation of the resource. Unlike in libraries like
SWR, the developer is responsible for keeping the
state in our State object in sync with the progress of the API calls. This
approach has an quite some advantages: we are more explictly handling effects
and understand better whether we risk calling twice the same API call for the
same data item. Plus, we are not bound to use a data-layout hidden in the
library: we make the relevant data immediately available in the State object.
There you oftentimes store the Remote information in the
Entity-Component-System, or at some other place convenient for mapping the
state onto the HTML tree (see Part-i).
The drawback I mentioned about having to manually update the state “in
sync-with” (note: a pun is loading) the progress of API calls actually is not a
blocker. Indeed, this endeavour is standard code in PureScript thanks to
MonadAff. In short, this MonadAff is a compiler hint to tell that at each
line of the do-block is an asynchronous step and the next step is to be
executed when the first resolves. As an Halogen library-user you are not
really concerned with this constraint, and you merely benefits from this
constraint (as a library author the constraint means you need to be cautious).
This mechanism enables us to write code sequential-looking code: as the query
progresses we modify our state by updating the Remoted object.
loadKitchenSinkArticles
:: forall m output slots. MonadAff m
=> H.HalogenM State Action slots output m Unit
loadKitchenSinkArticles = do
H.modify_ _ { kitchensinkSources = Loading }
resp <- H.liftAff $ KitchenSink.fetchPaths
case resp of
Left err ->
H.modify_ _ { kitchensinkSources = Errored (show err) }
Right jbody ->
case jbody of
Left jsonParsingErr ->
H.modify_ _ { kitchensinkSources = Errored (show jsonParsingErr) }
Right items -> do
H.modify_ _ { kitchensinkSources = Got items }Note: the KitchenSink module is a compatibility module mostly generated from my blog-generator, which let me have some up-to-date “news-from-the-blog” section in an app.
The presence of MonadAff in Halogen handlers is what contrasts the most with
Elm. While in Elm, we would handle every request state change as a top-level
action. PureScript helpfully takes care of turning the following code as
asynchronous spaghetti for us. MonadAff would even allows us to trivial have
more information inside the scope of loadKitchenSinkArticles if needed. In
React, users resort to fetching libraries like SWR because other orthogonal
concerns are non trivial in web-applications: we may need to reload a piece of
information for a same entity many times across the lifecycle of an
application.
Historical data types
Remote is a generally useful type. While iterating in my web-apps, I’ve come to the realization that web applications also need a few types to represent how we historize information.
Thanks to the ECS system with Seqnums, we naturally get an historical set of
information about entities.
Let’s say we have an application that needs to fetch Items with an image, a
price, a currency and so on. We could store them by representing as entities
the items in memory. Given that the data is remote, we will likely use a
Remote ItemInfo somewhere. If we nest this Remote data type in an object
having a Seqnum, it becomes natural to store multiple data-fetches for a same
itemId.
type ItemInfo =
{ itemId :: UUID "item"
, imageUrl :: Url
, price :: Int
, price_currency :: Currency
...
}
type ItemFetchedData =
{ seqnum :: Seqnum "item-data-fetch"
, itemId :: UUID "item"
, info :: Remote ItemInfo
}
type State =
{ entities ::
{ fetchedItems :: List ItemFetchedData
}
}The entities.fetchedItems field of the State can thus represent an history of
fetched data. We can use this history to perform any number of “summaries” via
some form of Folding technique
when consuming the State object (in views or in handlers).
A typical and familiar “summary” is to pick the latest item.
latestItem :: ItemId -> State -> Maybe (Remote ItemInfo)
latestItem id state =
List.find (\item -> item.itemId == id) state.entities.fetchedItemsThis function will pick the latest Remote ItemInfo, however this means
loading the latest-known data item as soon as we reload it. Sometimes we want
to keep the knowledge of the fact that an item is outdated. A typical sum-type
I use is Historical, which helps encoding the fact that a piece of
information has been never seen, is outdated (e.g., because we are reloading it
or resynchronizing it), or is expected to be the current last known state.
data Historical a
= UnheardOf
| Outdated a
| Current aWe can then lookup a Historical ItemInfo by extracting an ItemInfo from the
first non-loading, non-errored Remote, with a distinction whether a more-recent
Loading one exists.
In general, adding these utilitarian data types significantly reduces the risk of bugs and the risk of quirks in applications with multiple rendered sub-components.
Some care is required, however, to ensure that when picking a value among a
series of Remote ItemInfo we pick the relevant value. Most often, we want to
display the latest requested item, however some re-ordering can occur when
asking two data-versions concurrently: some re-ordering can occur.
It’s best to add some tests to ensure that your State-update functions do what
you want. But in short, if you do not store hundreds of fetchedItems at once,
you can keep appending fetchedItems as items are requested.: (i.e., the
left-most items in the array represent the latest-requested version). You can
then decide to keep or drop some Remote ItemInfo on a per-item-id basis.
Let’s present three obvious viewpoints.
- (somewhat common) decide to keep every transitions of what happend, use only
append, which mean deferring to the readers (at Fold-time) what to do with the history - (prevalent mode) decide to keep the data in the requested order: use
mapmodifying only the matching item - (less common) decide to keep the data in the response order: use
appendin the filtered to replace allfetchedItems
The picture below illustrates these viewpoints in case of event re-ordering.
For each viewpoint we play a same scenario showing a same sequence of events
and starting from the same state. Say we have a store of Remoted items, we
got a version b and a version a (older) of the item. Our application
requested in a short time span, two updates to the same item (update c then
update d, in this order), hence we are currently fetching the two versions
c and d (first row). Now let’s imagine the answer for d arrives (second
row) before the answer for c (third row). Then by applying a function based
on the viewpoint, you’ll get different fetchedItems at each step.
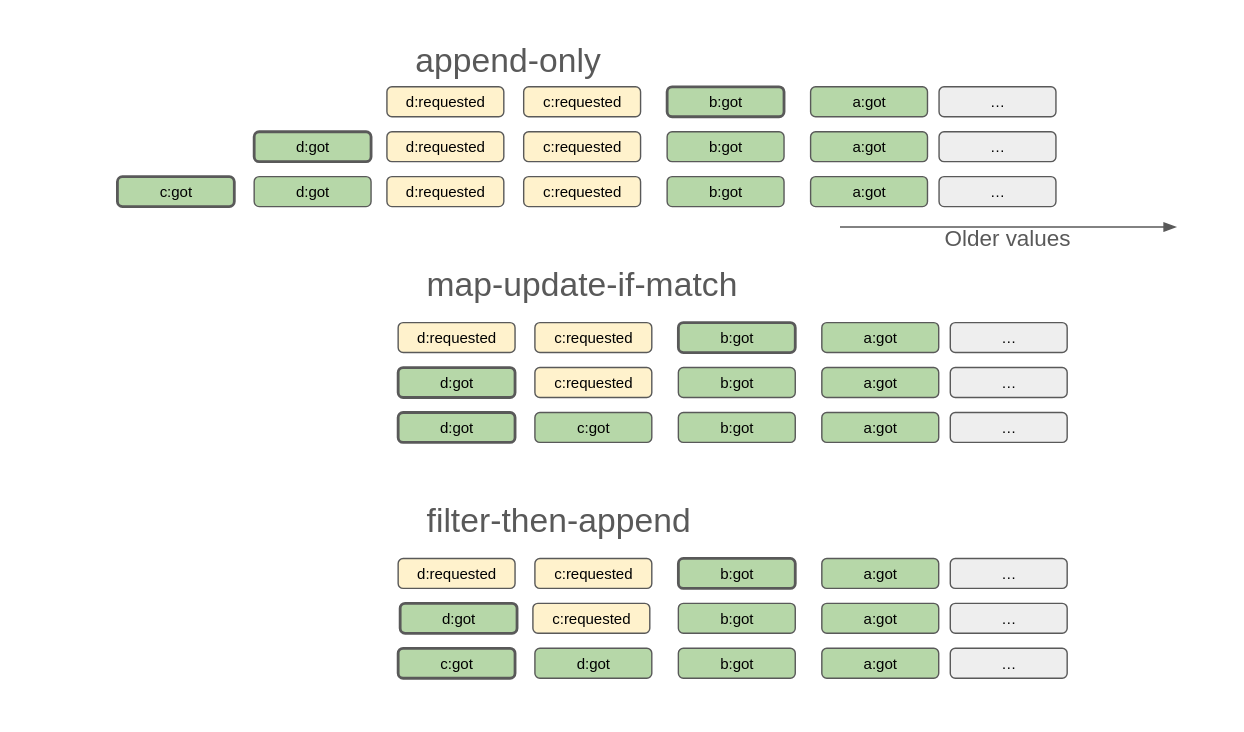
In bold, we pinpoint which is the item corresponding to the first Remote ItemInfo in the array of fetchedItems. Most often, you’ll want to display
the d value, but sometimes other viewpoints are useful. From experience, it
is also very often the case that, having an history is beneficial. Alas, the
implementation for the viewpoint “pick the latest requested value” is the least
natural think about. Using a fetching library will do “the right thing” for a
single viewpoint, with the downside that they could be of little help for other
viewpoints.
Fortunately, implementing a set of dedicated data type like Historical or
even LastThree, a fold, and an update function tailored to your use cases is
a matter of hours including tests. Further, if you come across a new use case
necessitating a new viewpoint on the history, you can compute the new viewpoint
aside, without porting the whole code-base to the new version. Just be careful
about showing consistent summaries to your users or they may see your
application “disagreeing” with itself (to pick on someone: for instance when
GCP Tasks’s console tells you zero tasks are in queue but the list below
definitely has some items).
Finally, do not overlook the fact that a long-running application then will need some strategies to clear the no-longer needed data, however the right strategy to use here is application-specific. You have to consider how fast you allocate and hold on memory for old values, which likely have decreasing utility as time passes.
Summarizing, in an API-world, we can use types to properly encode the dynamic behaviour of pages requesting and awaiting remote data items. At first glance it appears that you need to re-invent the wheel, but given that an Halogen application architected according to my recommendations will have some entities component system with increasing sequence numbers, we can consider Remote items as entities with sequence number themselves. This pattern allows to implement, with great simplicity, what is done in dedicated fetching libraries in React. Further, this pattern sets you up for when you want to make your application multi-users capable: you’ll need seqnums for just about anything. This is not a situation I’ve encountered yet, but I’m definitely looking into that direction these days (if you want to collaborate on such things).
Conclusion
This post closes a small series about how I architect PureScript applications with Halogen.
Overall, I’m very happy with the combination PureScript/Halogen, the language and the framework both are jewels of engineering and a joy to work with. In general I feel like PureScript’s typechecker, being fast enough, keeps me in the flow. To stay in flow I prefer to stick to simple naming guidelines, so that the application is mostly uniform: repetitive names in the modules and qualified imports at call sites.
Please keep in mind that if you found an obvious missing topic you consider important such as page-routing or i18n, Halogen/PureScript (or functional programming in general) may have a proper solution for these. Of course you may hit cases where neither PureScript nor Halogen have a good solution (e.g., performance wise, or if you need to write a web-based IDE or a super-performant simulation) but the easy interop with JavaScript really reduce the risks associated with using a somewhat niche toolset. I’ve not encoutered a blocker yet. Instead, I’ve documented what I think is core to my way of programming and topics somewhat under-served in other articles and documentation. I’ve already got some nice comment about stressing that the page State type and the IdealStateForRendering may have some impedance mismatch because the IdealStateForRendering should map to the page structure, whereas the application State will be shaped with other concerns in mind. In today’s article, I hope my discussion on how to configure web-apps via HTML-data-arguments will inspire others too.
I’ve not really covered the Halogen Component model on purpose because the Halogen Guide already does a good job at motivating and showcasing how Components work. Instead I want to stress, as a testament to Elm too, that you can reach very far and contain most of the complexity with a proper and simple architecture using a State object inspired from an Entity-Component-System. This “crude” technique for storing information happens to have many advantages in a world of web-apps having many concurrently executing API calls. PureScript is especially well suited to the task as MonadAff allows to write asynchronous code without spaghetti callback hell.
In pure-FP land, people resort to monad stacks and other tricks to enable logging. I find contravariant tracing and passing an extra arg around tolerable: it’s one of the most overlooked solution to log and analyze applications. Again, PureScript shines by making sure a component author controls the side-effects a Tracer introduces, while providing exhaustive checking on the component user side.
Stay tuned: I want to provide some demo-application or application starter pack as a synthesis of the guidelines found in this article.