How I write PureScript web-apps
On Sun, 09 Feb 2025, by @lucasdicioccio, 5215 words, 18 code snippets, 13 links, 6images.
This article summarizes how I now write PureScript/Halogen web applications. This article is heavy and contains a significant amount of information. Some familiarity with web-app development is required, while knowledge of PureScript/Halogen is preferred; without it, readers will need to be prepared to grasp some Haskell-like language.
I rely heavily on the product/sum-type duality principle (which I covered in another heavy article). In essence, product/sum-type duality is intricately linked with the producer/consumer duality. A creator of sum-types demands a product type from consumers, while conversely, consumers require a sum type from producers.
The article includes numerous code snippets and hand-wavy comparisons between Halogen and both Elm and React. It is hoped that this article will inspire readers to explore Halogen; otherwise, for those stuck in React, some principles remain applicable.
Short primer on Halogen: a sweet-spot for frontend apps
Halogen is a web-application library that plays a similar role to React in #JavaScript and the Elm programming language. Halogen is written in PureScript, a purely functional programming language from the Haskell lineage. PureScript compiles to JavaScript (but not only) and that’s about all you need to know for the rest of this article.
An Halogen application is tree of Components which are parameterized by:
- some internal state
- a pure, deterministic rendering function
- a set of actions internal to the component
- a handler function for the action type
- and a bit more things which are irrelevant at this stage
For instance, my Baby Words Game has the following code:
component
:: forall query output m. MonadAff m
=> GameData
-> H.Component query Input output m
component gamedata =
H.mkComponent
{ initialState
, render
, eval: H.mkEval (H.defaultEval { handleAction = handleAction })
}
where
initialState :: Input -> State
initialState input =
case input.question of
Nothing ->
NoQuestion
Just question ->
Solve
{question, attempts: 0, showHint: 0, guess: "", previousAttempts: [] }
render state =
HH.div
[ HP.class_ (HH.ClassName "game")
]
[ case state of
NoQuestion -> renderMissingQuestion
Solve pb -> renderSolve pb
Found w -> renderFound w
GaveUp w -> renderGaveUp w
, HH.div
[ HP.class_ (HH.ClassName "game-credits")
]
[ HH.p_ [ HH.text gamedata.credits ]
]
]
-- renderMissingQuestion ...
-- renderSolve ...
-- renderFound ...
-- renderGaveUp ...
handleAction act = do
st0 <- H.get
case st0 of
NoQuestion -> pure unit
Found _ -> pure unit
GaveUp _ -> pure unit
Solve pb0 -> handleActionPb pb0 act
handleActionPb pb0 =
case _ of
RevealHint k -> H.put $ Solve $ pb0 { showHint = 1 + k, attempts = pb0.attempts + 4 }
RevealAnswer -> H.put $ GaveUp { question : pb0.question }
Attempt k
| k == "" -> pure unit
| strEquals k pb0.question.actual ->
H.put $ Found { question : pb0.question , attempts : pb0.attempts + 1 }
| otherwise ->
H.put $ Solve $ pb0 { guess = "", attempts = pb0.attempts + 1, previousAttempts = cons k pb0.previousAttempts }
In this code excerpt, we recognize:
- a definition of a Component: that’s the name of a function returning Components (a
Factory-patternin Object-Oriented-Parlance), the function could have been namedmyBabyWordGameComponentFactorybutcomponentis just about right (we’ll come back to this later) - a definition of a render function (nested in the Component) with some HTML-worded syntax tree (
div,class_,p_), which is just a template-like DSL language embedded in PureScript - a reference to GameData, Input, and to some State : what is important is that these objects are properly typed, and that the type-checker ensures the application works within well-defined boundaries
- a pair of
handleActionfunctions to handle internalAction: what is important is that we can exhaustively check that we know how to handle any action in any state, that is the application may not crash nor turn into an unallowed state - quite some line noise about
query,MonadAffand more (that’s about all the noise you get in Halogen/PureScript but they are useful for more-advanced applications)
Since this article is not about making a tutorial on Halogen, let’s just
elaborate on the State. In my game application above, the Component’s
State is defined as follows:
data State
= NoQuestion
| Solve { question :: Question, attempts :: Int , showHint :: Int , guess :: String , previousAttempts :: Array String }
| Found { question :: Question , attempts :: Int }
| GaveUp { question :: Question }This data definition defines the State as having four possible shapes:
NoQuestion: we have not managed to load a dictionary of questions (and we somehow must say we are sorry)Solve: the user is actively playing, we need to remember the current guess, previous attemptsFound: the user has stopped playing and managed to find the answerGaveUp: the user has given-up playing and wants to see the answer
If you are familiar with the consumer/producer duality, you’ll immediately
recognize that these four mutually incompatible states naturally call for four
distinct rendering functions (render{MissingQuestion,Solve,Found,GaveUp}).
This code organization ensures that no default-value transient bug occurs:
imagine bugs like flashing a “you lost” message while we’re merely loading the
questions dataset. Reading the code excerpt above, you’ll also notice that we
specialize the handler function early: in a final state, the user should not be
allowed to input new attempt values. This style of programming, with simple
sum-types and product-handlers, is lean: what an application can do in a given
state is pretty transparent from reading the type definitions. You don’t need
advanced types to convey the overall guidelines as to how the Component should
work.
Another way to encode the same information using sum/product algebras to make
an AlternateState isomorphic to State (i.e., we can map from either
representation to another and back without losing information – encoding a
form of more-general equality than just “two values are equal”).
data AlternateState
= NoQuestion
| SomeQuestion { question :: Question, stage :: Stage }
data Stage
= Solve { attempts :: Int , showHint :: Int , guess :: String , previousAttempts :: Array String }
| Found { attempts :: Int }
| GaveUpUsing the AlternateState encoding, our render function would have two main
branches: depending on whether we could load some question dataset or not.
Then, the SomeQuestion branch would have three sub-branches. Wearing my
software-senior-hat, I’d first argue that given that either State and
AlternateState are isomorphic: the particular representation does not matter.
I could even see myself arguing in favor of the AlternateState style, as
factoring-out the notion of “Stage” can be a useful piece of information in
itself.
However, in the context of web applications, I find the “flattened” (i.e., when
we fully distribute) configuration better to start with. Indeed, the nesting
levels of a state object that you consume will naturally push you towards a
similar page structure, so that an extra indirection in the branch will sort of
force an extra html-tag-level. Henceforth, even though the choice among
isomorphic types to represent a Component state may not matter from a
quantity-of-information standpoint, it is the case that the particular
decomposition of this Component state is important and should reflect the
nesting you want on HTML pages. Hand-wavily: (a + b*c + b*d) = (a + b*(c+d))
however as far as mapping the two equations in HTML, the nesting or parentheses
matters.
Overall, Halogen strikes a pretty good balance between being a comprehensive framework that imposes its own conventions and mental models on your application, versus being a lightweight glue library with no guidance. Large frameworks often require you to adhere to certain structures and patterns that can feel unnatural and limiting. On the other hand, a glue library without guidance may lack consistency and cohesion, making it challenging to compose larger applications from disparate components. Having presented Halogen, for the rest of this article, I’ll refer to components as some ill-defined sub-part of a web application, reserving capitalized Component specifically for those defined by Halogen’s type system, which typically includes parameters such as Input, Output, internal State, and so on.
I also have quite some experience writing web-applications in #Elm and #React
with TypeScript. Compared to React, I appreciate the explicit definition of
inputs, states, actions, and effects in Halogen. For instance, given that React
components’ states are implicitly defined from the sequence of hooks like
useState and useMemo, you cannot rely on explicitly-given type to organize
your components and all the needed handlers.
Whereas, similar to Elm, I appreciate Halogen’s lean flow of using
sum/product-types to properly anticipate most unfortunate states. In contrast
to Elm, I appreciate the possibility of using any effect in my handlers without
resorting to JavaScript ports. Finally, PureScript is just a joy to work with.
Indeed, PureScript comes with a good type-system, easy JavaScript
interoperability, and a good amount of high-level combinator libraries (for
folding, traversing, and lensing structures).
The BabyWords game is a toy application. The full source code of this game resides within a single file of 356 lines of code, encompassing imports, initialization code to select an HTML tag in the document as the root of the application, and configuration derived from the URL’s query parameters. Larger applications like Postgrest-Table are proper engineering artifacts. Except for tests, the project comprises approximately 100 modules, including components and sub-components, user input forms, business rules, storage and API helpers, parsers, utility libraries, some logs and analytics, and what-have-you. Maintaining such an application necessitates a substantial amount of reusable patterns to ensure that despite its size, everything fits in my head.
Evolving a non-trivial application
We’ve already discussed how the State type in Halogen Components should mirror the HTML structure on the page, ensuring that rendering sub-functions and sub-components can be effectively mapped onto the State object. This constraint is alas hard to follow for large applications, which inherently involve intricate complexity.
We’ll discuss a few situations:
- When a large application exhibits a locality-mismatch in its application logic.
- When an impedance mismatch occurs between components and their sub-components.
- When some concerns force you to annotate extensive amounts of code.
locality mismatch
definition: locality mismatch occurs as some entity central to the application has some entanglement with otherwise-independent items scattered on a web-page, providing user-affordance and interaction knobs at various place.
example
A first example of locality-mismatch is error messages: although the source of an error may be local to a sub-component (e.g., a networking exception while preparing a counter in a “card” in a carousel of items). A user would expect all the exceptions to be collected in a central place (e.g., from a menu in the navigation bar). The components would then react to the user action in the error bar. There are different ways to handle such situations (mutable references or mutating directly in the HTML outside the virtual DOM, splitting concerns into two parts, avoiding entirely by making gigantic components).
Another locality-mismatch exists in application where a data-filter on a dashboard applies to many graphs and tables on a page. The fundamental issue is that a single state is operated upon by two or more places within the application. In Postgrest-Table, the prime example is the query-filter: navigating on a table should allow filtering based on the data seen directly in the table, but this is only a shortcut to the proper editor (which allows for a wider variety of changes, like configuring logical AND/OR filtering clauses).
source of the problem
The source of locality mismatch is an inherent problem with the desire to avoid repeated information (e.g., which Tab a user is focused on, whether there is a validation warning preventing to save an object) across different places. And the natural desire to have an HTML tree that maps nicely to the application state.
Take for example the following an application where users can pick a Tab between Write and PreviewArticle. Users can also have notifications. The rendered pages has initially two parts: a navigation bar and a main-tab bar. Notifications are used in the navigation bar, but we may want to show summaries from the current tab (e.g., the number of words written in an article).
The state will be as follows:
data Tab = WriteArticle | PreviewArticle
type State =
{ currentTab :: Tab
, notifications :: Array Notification
}We recognize a “product-type” with a currentTab (which is a “sum-type”) and
notifications (which is a more complex object). Let’s annotate these in blue and red.

However, the mockup for the application tells us something:
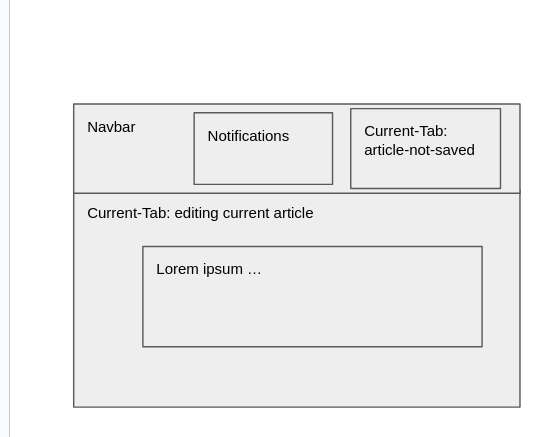
We can illustrate the locality problem: the nesting of rendering functions (or HTML tags) we get is as follows:

This nesting indicates that the red and blue circles are not positioned in the rendering function like they are in the State definition. By mapping back from the mock-up, we can define an ideal state, where product-and-sum-types align properly:

which, written out gives us
type IdealStateForRendering =
{ navbarState ::
{ notifications :: Array Notification
, currentTab :: Tab
}
, currentTab :: Tab
}which contrasts, having duplication and so on from the original State.
Thus, a solution would be to have a function State -> IdealStateForRendering.
Alas, each time we would move a component around we would have to adjust the
IdealState object as well as the mapping function from State to IdealState
and tests and so-on. As far as I can tell, this approach would work and would
provide nice advantages, but the coupling would likely be cumbersome and
iterating on frontend components would have too much friction. Another
solution I dream of would be to devise an entirely-different programming
language with these sort of transform at their core. I may try either of these
approach one day. Meanwhile, I devised another pragmatic solution: getting
inspiration from Entity-Component-Systems.
solution pattern: use a gigantic component with an Entity-Component-System-inspired state
The root of the issue with locality-mismatch is that our web-frameworks and
web-libraries tie tightly the existence of entities in states to the existence
of components. The solution is to enforce a single ownership of entities at the
top-most component (which I sometimes refer as the Page component). This
solution is roughly what Elm forces onto you because the whole application
lives in a single component. In theory you should be able to do the same in
React, but its focus on having sub-components would force passing a family of
decorated setState() functions down the stack, with no control on how-many
times a given handler is called. Whereas I feel it’s more natural to just
capture the sum on inner events at the top-level (plus the type-checker forces
you to handle everything).
Indeed, I believe sub-components should only access entities using a state passed via a read-only references. Thus, I believe the React way of doing thing: that is, passing hidden mutable references hidden in handlers is morally wrong in my compass. I prefer the Elm standpoint that a top-level component should be responsible for holding the state of each individual entity. Sub-components are free to copy and “mutate” a local versions of the entity (e.g., to show a “diff” before committing the change to the rest of the application), however they should communicate back their change via actions that are handled in the top-level main loop.
An extra benefit of this approach is that our application funnels all emitted action-events to our top-most application component, which can then act, perform side-effects, and update its child components only once. This mechanism simplifies the logical flow of updates and allows the programmer to have tight control over side-effects; unlike in say React, where we often end up with miscellaneous API calls from sub-components that have unclear dependencies. Compared to Elm, Halogen allows arbitrary handlers in the handler function, which means you still have some wiggle room to perform tasks like making Ajax calls or writing local storage directly within the handler functions.
A significant drawback of this approach is that you now have a massive State object. Organizing the data within this object can be quite complex. My preferred solution involves using a simple Entity-Component-System paired with functional helpers, such as filters, lenses, and traversals, to efficiently operate on subsets of entities at once.
The Cheap Entity-Component-System
In my viewpoint full of simplifications, an Entity-Component-System (ECS) is just an in-memory tabular database.
Henceforth, the cheap-Entity-Component-System is just a cheap-in-memory tabular database. In this database, individual entities are stored in an Array of entities, one Array of entities exist per type of entity. Apologies, if the previous sentence was hard to parse, let’s clarify this unfortunate sentence with an example.
type State = {
entities :: {
users :: Array User
, posts :: Array Post
, likes :: Array Like
, comments :: Array Comments
}
}To address (as giving an address by which we can locate objects) to entities, I
use a typed sequence number per entity. Here PureScript shines because I can
just newtype Integers once and use the type-level string to tell what sort of
Integer I’m using. This way, we cannot make mistakes like confusing a userId
with a commentId, further we can force users allocate new SeqNums with care.
newtype SeqNum entityTypeName = SeqNum Int
type User =
{ seqnum :: SeqNum "user"
, displayName :: DisplayName
, avatarUrl :: Url "avatar"
}
type Post =
{ seqnum :: SeqNum "post"
, authorSeqnum :: SeqNum "user"
, title :: String
, contents :: Markdown
}The last issue to solve is properly allocating a sequence number so that
duplication cannot occur. In the tools I’ve made, introducing a SeqNum is done
via a function named allocate, which can only run as an Halogen action
handler on a component with a central “seqnum” counter. Thus, thanks to
PureScript’s type system, I can enforce that all sequence numbers are
increasing. Allocating a sequence number is treated like performing a network
request, and this effect is well-understood by the programmer as it cannot
occur outside event-handler functions.
Each application can then specialize some functions to create, remove,
update entities. A create requires to (i) allocate a seqnum (ii) appending
a new User in the global state, a delete is a filter, an update is (i) a
lookup (ii) creating a modified value (iii) inserting the modified value (iv)
removing the old value.
Let’s illustrate how a create would look like:
handle (CreateUser displayName avatarUrl) = do
seqnum <- SeqNum.allocate
let newUser = {seqnum, displayName, avatarUrl}
H.modify_ (\st0 -> { entities { users = append newUser st0.entities.users } }Here H.modify_ is a Halogen primitive to mutate the component state. From the
application viewpoint, this call is like atomically swapping the state with a
modified copy. This atomicity property solves problems you may encounter in React
where a modification triggers more re-render than necessary, or when a rogue
setState with a value surfaces an outdated value. Note the SeqNum.allocate
behinds the scene also calls H.modify_, which ensures we allocate sequence
numbers atomically for our application, and only in handlers.
I personally enjoy how nice the nested-record update syntax is in PureScript.
For more involved updates, I recommend extracting the whole State -> State
function in a separate function that you can test aside.
In a proper ECS you’d go further and push more and more properties in arrays, however as far my applications have been concerned, high-level entities with plenty of sometimes-duplicated properties (like “title”) are fine.
summary
To handle issues with locality-mismatch between entities being split across HTML sub-trees, we use a page-global cheap-Entity-Component-System. PureScript has nice syntax and semantics to ensure the ECS is atomic and to prevent clerical errors. Sub-components agnostic of entities may exist, and will need to communicate back messages to the topmost component handler.
However, communicating back message is non trivial as sub-components (say a delete button) should have limited knowledge of the precise entity they are operating on. This tension arises from an impedance mismatch between the desire to make domain-specific, business-heavy actions in the parent component and bland, technical events of children components.
impedance mismatch between components and their sibling
As an application renders, the application runtime sort of translates business-logic into HTML tags in the browser. Application components implementing business processes are translated into bland items that do not understand business logic. Unlike a compiler which operates between languages at different levels, a web application library like React or Halogen asks users to write business-level code entangled with HTML and web-browser primitives. As a result, there often is ambiguity about what primitives a given component should expose.
pages
Pages are the out-most component of web-apps, controlling all of the DOM. Even
though they could be nested under other components, doing so would be
inconvenient: for instance, a Page will have a navigation bar at the top of the
application, which means the value of nesting a Page within a Page
is dubious. Because Pages are responsible for the main State and the main
handler loop, they have a privileged role. I recommend starting application
from a single Main module instantiating a main Page. The Page exposes a
Component. I name the “rendering function” render. Then, as the business
evolves, I spit-out sub-components but this process only arrives late. My
favorite way of writing non-trivial rendering functions is to use long names
and repeat intermediary scope. Let me explain.
I initially implement my render function by splitting it along branches, and
while I create new branches, I suffix the render function further and pass as
many from arguments accessible at every branch.
Say you have the following state:
data Tab
= TabUser User (Array Article)
| TabGallery Gallery (Array Image)
data State
= State
{ activeTab :: Tab
}Then a render function will likely want to branch somewhere on the active
tab. Thus, one place (or many) will likely have a to pattern-match on the
activeTab and branch whether on _user or branch on _gallery, at each
branch, we can pick whatever is contained inside the Tab-specific object.
render state =
HH.div_
[ HH.title_ [ HH.text "my wonderful example application" ]
, case state.activeTab of
(TabUser user articles) ->
render_user state user articles
(TabGallery gallery images)
render_gallery state gallery images
]
render_user state user articles =
HH.div_
[ HH.p_ [ HH.text user.name ]
, HH.div_
$ map (render_user_article state user articles) articles
]
render_gallery state gallery images =
....Recall that at this point we are high in rendering layers of the Page component. In practice, we do not really know what sub-component will need which parts of the State. Conversely, any sub-component may one day require some piece of information from the whole state or anything accessible scope above. It is hard to foresee how feature will evolve, especially on the frontend, thus, my viewpoint is to be generous: pass anything that may be needed. Given that we are in pure functional programming, adding an extra parameter is something natural.
Since we may have many rendering function and sub-rendering functions, explicit typing can add a lot of line noise. My preferred convention is to:
- suffix the sub-render function (hence we end up with
render_foo_bar_baz_blah) - add extra params accessible along the paths (hence we end up with
render_..._bla state foo bar baz bla– which make a lot of unused parameters, but it’s a price I’m ready to pay)
For instance, for rendering a single article, we pass all information along the tree, starting from the Page’s state to a function named using all the branches starting from the root.
render_user_article state user articles article =
HH.div_
[ HH.h4_ [ HH.text article.title ]
, HH.p_ [ HH.text article.contents ]
]Overall, if verbose, one benefit of the approach is that it cost little
brain-power (for adding new rendering sub-components, for navigating in the
code etc.). Another benefit of the approach is if the State naturally has
multiple branchy objects, we can reflect this in the function names, reflecting
which branch is taken in which order. Compare
render_user_article_inEditMode_title and
render_inEditMode_user_article_title, which hints at whether the page has an
Edit-mode for articles (and maybe not for gallery images) or the Edit-mode is
specialized to articles.
This approach is indeed generous: pass more than what is needed as it does not cost us much. Making a whole separate component in a whole different module and tailored to take only the right parameters in another file would be dispendious.
On may ask: where do we stop? In practice, applications have buttons, lists, panels etc. There is a tolerance-limit to how-long the function names can be. In particular, towards leave, we reach a place where the rendering-content is close to the realm of bland HTML. We ignore almost all parameters we gleaned on the way. Such a characterization is a good signal to actually split a function into its own module, which I categorize in Bricks and Widgets.
bricks
The first family of sub-components that we want to isolate and re-use are HTML
primitives. Ideally, a Delete User button, in HTML, should primarily be a
Delete button. In all likelihood, such button may have a reference to a
SeqNum “user” but the only use of this reference should be to annotate the
onClick event. In the real-world, bricks will consist on some nesting of
div and spans with well-positioned CSS classes that are specific to your
CSS toolkit (I like Bulma as it requires no dedicated-JS).
In short, we want Bricks to have the following characteristics:
- captures HTML boilerplate, provided some inputs (texts, CSS-classes etc)
- allow some tuning of content that is not-interested in the specific item
- allows to emit events chosen by the call-site
PureScript type-system you can enforce that every button has some tool-tip. I refer to these “leaf components”, bland of opinions as Bricks.
My favorite pattern for Bricks is to rely heavily on the PureScript syntax and
semantics. The naming is always regular: the module name captures the specific
Brick, then type and functions we exports are almost always named as follows:
Props and render.
Let’s show-off the syntax first for my “ActionButton”.
module Bricks.ActionButton where
import Prelude (($),(<>),show,const)
import Data.Array as Array
import Halogen as H
import Halogen.HTML as HH
import Halogen.HTML.Events as HE
import Halogen.HTML.Properties as HP
type Props a =
{ text :: String
, action :: a
, disabled :: Boolean
, info :: String
}
render :: forall a. Props a -> HH.ComponentHTML a s m
render props =
HH.button
[ HP.classes [ HH.ClassName "button" ]
, HP.title props.info
, HE.onClick (const props.action)
, HP.disabled props.disabled
]
[ HH.text props.text
]Then, at call-sites, I use qualified-imports for Bricks.
import Bricks.ActionButton as ActionButton
-- the actions that I may have to handle
data Action
= InitializePage
| ...
| PublishArticle (Seqnum "article")
| DestroyArticle (Seqnum "article")
| ...
--- somewhere in the render-family of functions
render_article state article =
let
disabled = somePredicateBasedOnStateAndArticle state article
in
HH.div_
[ HH.h4_ [ HH.text article.title ]
, HH.p_ [ HH.text article.contents ]
, ActionButton.render
{ text: "publish"
, action: PublishArticle article.seqnum
, disabled
, info: "publish the article to your portfolio website"
}
, ActionButton.render
{ text: "destroy"
, action: DestroyArticle article.seqnum
, disabled
, info: "deletes the article from the Internet, you cannot revert this"
}
]
--- the handling site:
handle action =
case action of
InitializePage -> ...
...
PublishArticle articleSeqnum -> do
article <- fmap (lookupArticleBySeqnum articleSeqnum) H.get
for_ article $ \art ->
performAjaxCallToPublishAnArticle art
DestroyArticle articleSeqnum -> do
let removeArticle = Array.filter (\art -> art.seqnum /= articleSeqnum)
H.modify_ (\st0 -> { entities { articles = removeArticle st0.entities.articles } }
...Using this pattern, the call-site seems pretty regular compared to normal “HTML-templating” PureScript. The event-handling is localized, API-calls reside in libraries, the set of possible actions is known at compile time, and the application is kept honest (we cannot easily mix handlers, we cannot easily mix entity-type and delete an article given an user-id).
Despite its simplicity, it’s worth spending some time on the ActionButton’s
semantics. The input params are parameterized by a single type: the actions that
the call-site knows how to handle. This is a fundamental difference with React
and where PureScript is safer than React. In React a similar button would take
an onClick handler. The problem is that onClick handlers may hide any
references to mutate objects encountered down the path; further, the handler
handler can perform unholy side-effects like an unprofessional
console.log("ocus-pocus") left by mistake. Most of the time you hope your
handler is well-behaved but you have no way to enforce it. You just squint and
sweat. PureScript/Halogen keeps your components honest: actions are just
in-animate objects, the ActionButton cannot misuse a handler and all the
state-modifications are easy to track-down.
Summarizing, Bricks allow for uniformity in the button/icon charter throughout the application. Bricks limit the multiplication of Button in various combinations like UserDeleteButton, LikeArticleButton, LikeArticleButtonButInCollapsedMode etc. They are not, however, a magical tool to fully-prevent bifurcating types when it is necessary to adapt a Brick to a specific component. Bifurcation just does not occur upfront but only when required.
going further than call-site-defined events
Bricks can become more complicated than a simple button with a call-site-defined event. Sometimes you want the call-site to customize some of the rendering.
For instance, say you need a Tag List, where you have some items that you can remove. The special coloring, font, and so-on is too business-heavy for the Tag List. Users may even want to add links or bind other events while clicking on the Tag. Well, in that case you need to be clever and:
- deliver some boilerplate in accordance to your CSS framework, adding a delete-cross button to delete the tag
- let the caller take control of the inner rendering function
- convince caller you are honest
An approach is to use parametric types.
module Bricks.TagList where
... imports ...
type Props item a s m =
{ items :: Array item
, contents :: item -> H.ComponentHTML a s m
, onDelete :: item -> Maybe a
}
render :: forall item a s m. Props item a s m -> H.ComponentHTML a s m
render props =
HH.div
[ HP.classes [ HH.ClassName "tags" ]
]
$ map (render_item props) props.items
render_item :: forall item a s m. Props item a s m -> item -> H.ComponentHTML a s m
render_item props item =
HH.span
[ HP.classes [ HH.ClassName "tag" ]
]
[ props.contents item
, case props.onDelete item of
Nothing -> HH.text ""
Just action ->
HH.button
[ HP.classes [ HH.ClassName "delete" , HH.ClassName "is-small" ]
, HE.onClick (const action)
]
[
]
]A key characteristics is that a TagList brick does not care much about the
business logic of the items (the property you may want to lookup is
parametricity). But we know,
looking only at Props that our TagList is gonna work on items, and the
only thing we can do with these items is: render them according to a contents
function or fire and event to signal the end-user wants to delete the item.
The call site would look like this (provided you also have a Link Brick and some Icon Brick):
render_article state article =
HH.div_
[ HH.h4_ [ HH.text article.title ]
, HH.div_
[ TagList.render
{ items: article.tags
, contents: \tag ->
HH.span_
[ Link.render
{ text: tag.name
, url: MyBlogBizrules.tagUrl tag
}
, Icon.render
{ icon: "tag"
}
]
, delete: \tag -> false --here we never allow to delete tags
}
]
, HH.p_ [ HH.text article.contents ]
, ... more like the publish buttons
]Clean, isn’t it?
If we run our Brick checklist, TagList is a Brick. Indeed, it captures (non-trivial) boilerplate, allowing the tuning of the contents, with conditions to add or not a “delete” cross, and it let users pick the events to fire on the delete-button.
combination of events
Recall that I like sum-product dualities. When writing a Brick, I’m obsessed
with the duality. Indeed, in the case where a Brick has not one but multiple
user-defined events. For instance-lets imagine a Brick to define a missing
HTML primitive, say a Rock-Paper-Scissor input button that allows to chose a
Rock, a Paper, or Scissors.
We are facing a nice design choice. We can pick to equivalent Props for our bricks.
module Bricks.RockPaperScissors1 where
...
type Props a =
{ onRock :: a
, onPaper :: a
, onScissors :: a
}
...is isomorphic to
module Bricks.RockPaperScissors2 where
...
data Choice = Rock | Paper | Scissor
type Props a =
{ onChoice :: Choice -> a
}
...both implementation say “if you want a Rock-Paper-Scissor component, you need to prove me you know how to handle every single branch”.
As a Brick author, you may not have huge preference and both are equally useful. But put yourself in the shoes of the Brick library users to think about what it the most natural.
Consider the difference in terms of Action constructors at the call-site:
data Action
= InitializePage
...
| OnRock
| OnPaper
| OnScissorvs.
data Action
= InitializePage
...
| OnRockPaperScissor ChoiceIn general, it is worth spending some time thinking about the shape of your handlers. For simple sum-types I prefer the latter style with a single handler. For nested sum-types it may be worth considering which one you want:
type Props1 a =
{ onFooBarBaz :: Either String (Maybe Int) -> a
}vs.
type Props2 a =
{ onFoo :: String -> a
, onBar :: Int -> a
, onBaz :: a
}Fortunately, PureScript does not shy away and adapting the Brick props at the call-site is still pretty.
drawbacks: the state has to be managed outside
The main (and only?) drawback of the Bricks definition is that Bricks cannot
have an inner state. As a result, you need to pass the state (say a
“confirm-delete” state) as extra field in the Prop.
In Halogen, you can use Slots to wrap proper Components with their own
internal state. Slots are a pretty powerful construct but I think they cost too
much boilerplate at the call-site (in terms of type-level sorcery) for what are
merely Bricks of HTML. I want to use a lot of Bricks.
The way I end-up organizing these is by considering that the Page State has an
UIState, and considering the various UIStates like entities in the ECS.
type ArticleUIState =
{ articleSeqnum :: Seqnum "article"
, userHasPressedDeleteOnceAlready :: Boolean --note: better to use a proper sum-type about the deletion-process-state
}Then, I can lookup an array of items from within the State object. On the Action and handler side, some bookkeeping is then needed to ensure the handler modifies the ArticleUIState on a DestroyArticle event.
An Halogen-Slot-based solution would be to have a Slot storing one
“ButtonWithConfirmation” Component in a userHasPressedDeleteOnceAlready field,
and indexed by Seqnum "article". With this setup, you’d end up with a very
similar to what I propose in the ECS. However, Slots also come with plenty of
tradeoffs (e.g., they re-render based on Input changes, it becomes less natural
to determine the component state from other items, we need to query them to
probe the inner state etc) although they also bring benefits (e.g., they take a
bit of complexity off the Page Action-type and Handler-function). Oftentimes I
reserve Components for large stateful application parts that could almost
become Page themselves (such as the Endpoint configurator).
widgets
In a real application, comes some point where you really need or want to wrap, instantiate, or decorate somehow, the DeleteButton. For instance you may want a custom UserDeleteButtonForFirstOfApril displaying a Users’ avatar with a sad-face or whatever creative thing you come-up with. Sometimes these evolved bricks have even more non-trivial business logic in them.
From a technical standpoint, little distinguish Widgets from Bricks however from a philosophical and practical aspect I prefer to name Widgets the bricks that directly mix some business-logic or application-specific-ontology. Say, an Comment-list, if you want to reuse the Comment-lists for Users in the Images rendering aspect (because of Avatars and so on) or some very-specific action aspect (e.g., CensorComment).
My mental model is that Widgets allow to provide templates of domain-specific events. For instance, in Postgrest-Table, when you click in a cell of a table, we want to perform actions that are in the domain of spreadsheet actions (e.g., copying the value, pasting it directly in another input, updating the query-filter to filter out the value etc.) Thus, while writing such domain-rich components, you are drawn to use an Action type defined in terms of the domain, in contrast with Bricks which define handlers in terms of HTML events.
module Widgets.Cell where
data Action
= CopyValueToClipboard String
| AssignValueToDestination Destination String
| ExcludeValueFromQuery String
type Props a s m =
{ value :: String
, showPopUpMenu :: Boolean
, handleAction :: Action -> a
, possibleDestinationsOfValue :: Array Destination
}In short, the key distinction between Bricks and Widgets is that a Brick is almost domain agnostic. The caller of the Brick is encouraged to directly map low-level events into application-specific events. Whereas for Widgets, the caller is encouraged to merely annotate the Widget event with some Entity-address, and the mapping is being done at the handler-site.
Let me illustrate with an example using an ActionButton Brick and the CellWidget above:
module Page.MyApp where
import Bricks.ActionButton as ActionButton
import Widgets.Cell as CellWidget
data Action
= ResetApplication
| HandleCellEvent (Seqnum "cell") CellWidget.Action
render state =
HH.div_
[ ActionButton.render
{ text: "reset"
, action: ResetApplication
, disabled: false
, info: "tabula rasa"
}
, HH.ul_
$ map (render_cell state) state.cells
]
render_cell state cell =
let
ui = fromMaybe defaultCellUI (findCellUI state.uis.cell cell.seqnum)
in
HH.li_
[ CellWidget.render
{ value: cell.value
, showPopUpMenu: ui.showPopUpMenu
, handleAction: HandleCellEvent cell.seqnum
, possibleDestinationsOfValue: []
}
]There is quite a lot in the code above to make the example look like it’s true
code, we have a Page that requires a ActionButton Brick and a CellWidget
Widget. From a caller perspective, both the ActionButton and the CellWidget
feel similar, however the subtle difference is in the Page Action type: the
Brick event has been directly mapped into an Action whereas the HandleCellEvent
has merely been deferred to the handler code.
These two patterns correspond to two ways of composing a Page from smaller components:
- We abstract away the Bricks: as far as the Page is concerned, a
ResetApplicationcould come from a timer. - Whereas we delegate a subset of the Action domain to Widgets: we annotate the provenance of the Widget and, if the Widget evolved to support new events, the Page will have to handle these new events.
This distinction is important: there is a difference in the nature of the dependency from Page onto Widgets on one hand, an the dependency from Page onto Bricks on the other hand. Hence, it is useful to move Widgets to their own directory tree because they will likely force some imports on inner models and may be prone to import cycles. Besides this key distinction, there is not much to say about them we have not already said about Bricks.
summary
Challenges abund in real applications. On one-hand: increasing amount of states are required to provide a good user experience and visual clues, on the other-hand you need to mix business concerns as a simple HTML selector becomes a “workflow-for-my-application” selectors with extra validations and so on. Essential and accidental complexity grows as an application scope grows.
We can manage the increasing complexity by organizing our code in a specific
way. First, we can manage state for Bricks by storing the UI-specific state of
bricks and components as part of the Entity-Component-System. Second, we can
prevent business concerns creeping in technical concerns by separating Pages,
Widgets, and Bricks even though they are pretty similar if we squint.
Widgets live at the boundary between Pages and Bricks, and some care is
required to keep a sane Action type and to prevent import cycles in
definitions.
The Entity-Component-System is embedded in the Page state, every primary entity gets stored in an Array, much like a relational database. UI components which require an advanced amount of state also can be stored as array items in the ECS.
This nesting is summarized in the following image:
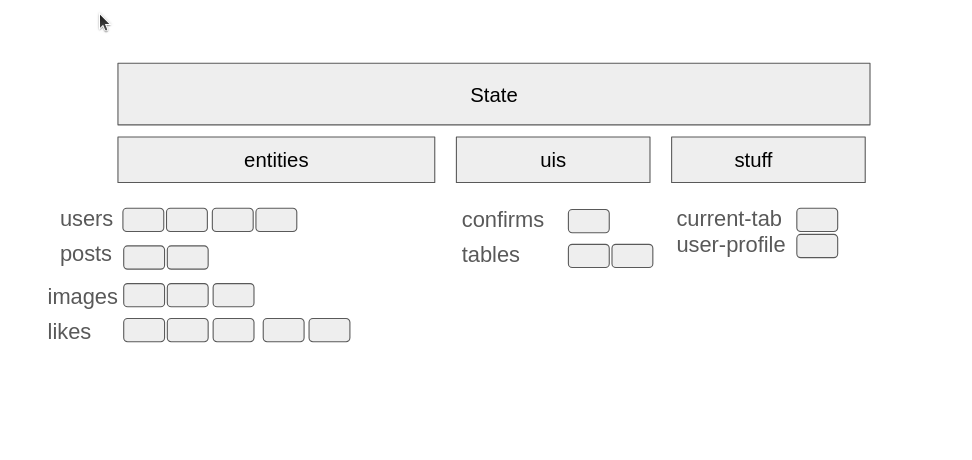
A web-page may comprise hundreds of components and thousands of HTML tags, hence
we need to organize our code as well. Two fundamental pillars allow to tame the
complexity: First, rely on the import system to qualify imports, so that every
component as a regular shape: a Props object parameterized on the action, and
a render function. Second, consider whether the component is a Widget or a
Bricks. The characterizing difference between either is whether the component
will be mapped into an Action (for Bricks), or rather whether the component
extends the realm of Action (for Widgets). It is useful to know the
distinction between mapping and
contramapping because that is
essentially what differentiates the Widgets from the Bricks.
These guidelines are summarized in the following image.
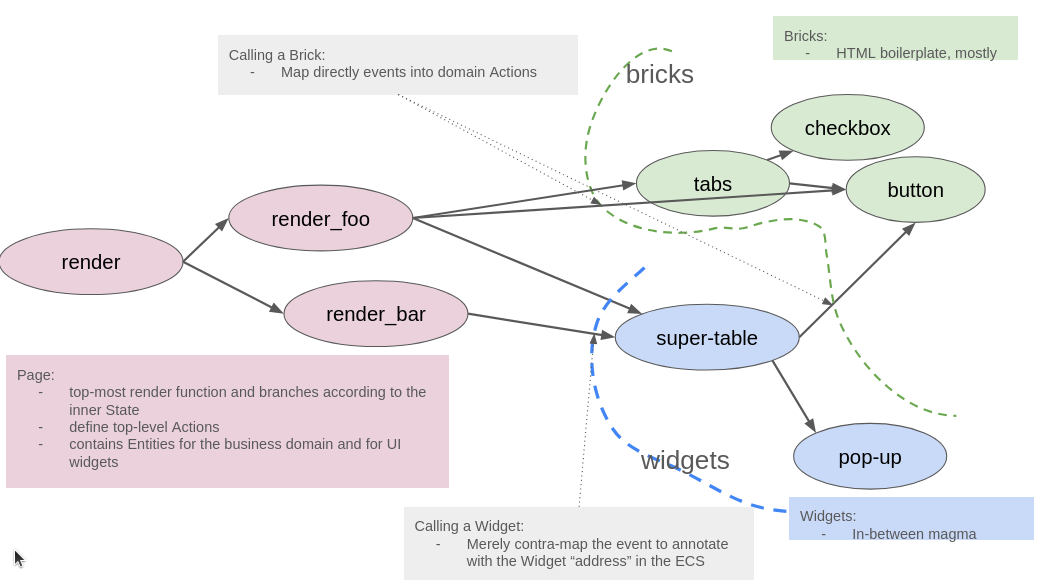
Finally, an overarching concept in the way we write applications is that the branchy-ness of the application and the nested-ness of components should be reflected in the Page State and Action, which in turns produces guidelines as to how to organize code.
- nested-ness is handled by suffixing increasingly-lager
render_foo,render_foo_barfunctions with arguments gleaning information along the way. - branchy-ness (e.g., which Tab a given component is focused on) should invite a sum-type in the state and the creation of multiple render-branch, one per case.
If you’ve made it this far, stay tuned. In a future article I’ll discuss cross-cutting concerns and somewhat advanced topics so that you become prepared to write your next web-application in PureScript/Halogen. In the future I plan to open-source my “minitools” library of Bricks and utilities I extracted out of Postgrest-Table and Prometheus Monitor. If this post gets some visibility, I’ll also prepare some toy-example template application.