The technology behind this blog
On Sun, 30 Jan 2022, by @lucasdicioccio, 3337 words, 2 code snippets, 21 links, 3images.
I wasn’t #blogging much. I used to prefer giving meetup talks, then the pandemic came and I wanted to start blogging a bit. I wrote nothing, mostly due to the lack of blogging platform I liked. This year, one resolution I took is to remediate this situation and start writing some technical content. After past and more recent attempts at using a SAAS blogging platform, hosting a Wordpress, or generating a Jekyll site, or hand-written HTML files; I always got frustrated.
I always felt some friction between writing content and laying-out content. Writing requires some uninterrupted stream of thought, whereas formatting HTML require focus and repeated trial-and-errors cycles. Writing the text in one document and then formatting the HTML aside in another tool typically is not sufficient because any change requires modifications in multiple places.
Without much surprise, I ended up writing my own engine. This article explains what I really want of a blog-engine and how I’ve implemented it. Little code is shown and ideas are applicable whatever tech-stack you pick.
Requirements
Let’s make a checklist
- static-site first, APIs second
- live preview with auto reload
- markdown for the meaty content, functional layouts
- customizable CSS, JS per article
- metadata for layout and stats
static-site first, serving second
Hosting a static site is much simpler. GitHub does it for free. At this point I cannot justify maintaining API endpoints for posting comments, nor a database to store them. I still would like to be able to fluidly move to something beefier with a web server. When such a move arises, I would not want to have to port all the meaty content. That is, if I occasionally need an API call, I can still imagine having a static-site first, with only a meager amount of web-serving.
A nice side-effect is that git is a natural database of content, and
git-based flows could serve in multi-authors situations (or for instance to let
people use GitHub to add invited-content/comments on the blog).
developer mode with live-preview
I like quick feedback loops. The fastest feedback loop I can think of is a WYSIWYG editor. However my experience with WYSIWYG is not great. To make WYSIWYG works, tools require pretty stringent feature constraints. For instance it is hard to be consistent across pages due to the free-hand nature of WYSIWYG tools. WYSIWYG tools work with their internal and opaque data structures, which then hinder composition with other software and may have challenging upgrade paths.
From experience with LaTeX and markdown in GitHub/GitLab documents, I think a fast-preview is good enough. A Live-preview like in HTML-IDE is almost as good as the immediacy of WYSIWYG. Given that I am writing HTML content, I could use a JS script to automatically reload after changes like some JS applications frameworks (e.g., NextJS) offer.
markdown for the meaty content, functional layouts
To make a blog page you need two broad set of HTML information, the meaty content and the layout parts. The meaty content is the large amount of words and paragraphs and images that make the core of the site. This is what readers are interested in. The layout is what readers (and robots) need to navigate and discover the content. The layout adds some wrapping and normalization of headers, footers etc.
To write meaty-content, you typically want a language with little line-noise
than then renders to HTML chunks. Platforms have a variety of syntax for
this. For instance, Wikipedia has its own format with specific features to
recognize links between articles etc. Beside supporting a ‘flow of
consciousness’ approach, these formats are good because we can easily re-use
existing tooling such as the aspell spellchecker, grep to locate some
keywords without too much false-positive. For my own blog I settled on
Commonmark which is roughly
enhanced-markdown-with-a-proper-spec. Commonmark has been invented by one
author of Pandoc, which gives a lot of credit to the initiative.
In tension with the “meaty content” is the “layout”. We need to wrap out meaty
content with repetitive information but also with a fair amount of
article-specific dynamic information (e.g., the publication date should always
be at the same position, a list of keywords should be present when keywords are
present). I need some automated templating to achieve a proper layout, some
templating languages exist like Mustache,
Haml, GoTemplate, but
I always felt the overhead of learning these specific syntaxes and using these
outweighs their benefit. Let me elaborate a bit: these templating languages
are constrained to avoid doing things like starting a web-server while
rendering some HTML. They support constructs like iterations into structures
for repeated information (e.g., for each tag add a <li>{{tag.name}}</li>
content). This is all good, however for any non-trivial layout, you end up
preparing a very specific data structure with all the right computations (e.g.,
sorting, numbering things). In the end, you need to morally prepare your
template twice: first in the rendering to HTML in the template language itself,
a second time in the data structure you pass to the template engine. Maintenance
is complicated, and you lose a lot of type checking benefits at the boundary
between your main language and your templating language. In short, you gained
little at extra cost.
In my opinion, templating and layout are solved by restricting oneselves to
pure-functions from some dataset to an HTML structure DataSet -> HTML. Hence,
functional programming is the right tool for the job. I happen to know Haskell
well, the author of Commonmark wrote a couple of libraries in Haskell
➡️ overall I have no reasons to shy away and pick something
different.
customizable metadata, CSS, JS per article
I have ideas for some articles that would benefit from having special CSS or special JS scripts (e.g., to add some interactivity). Ideally, I want the ability to insert assets on a per-page basis. Since there are different reasons for inserting a specific asset (e.g., the layout is different for a generated article listing than for a normal article), customization could be written at the Haskell side or in the meaty content but in most cases we should configure that from the meaty content. Ideally, I would type multiple sections in a single file to avoid spreading what is a single article into many files with a proper directory structure (I don’t enjoy structuring directories until I feel enough pain to do so). An example of files with sections are multipart-emails. And your email client can totally make sense of images, HTML parts, text parts from a condensed text file. Let’s take inspiration on this.
Synthesis of requirements
The thing I want is some Haskell-variant that (a) interprets markdown-like files for the meaty content then passes that into (b) some rendering function. These files could (c) be augmented with extra data and extra CSS/JS. The tool I want would have a generate-static-site and a serve-on-the-fly-files to accommodate the ambivalent ‘static but also live but also with an API if I want one day’ aspects.
I don’t really want to invest time in learning something that will be irritating in one of these dimensions. Established tools may be too rigid to accommodate some of my quirks. The closest tool I found likely is Hakyll, a Haskell static-site generation library. It supports some form of metadata per-article for customizing the article (e.g., picking a certain layout) but I really want to insert multiple sections.
Thus, overall, I got a pretext to invent my own 🤓 .
Implementation
Let’s first say that the implementation I present here does not represent the
whole iterations. I first started with a simple file-to-file generator taking
exactly one .cmark file with multiple sections and turning that into .html + .css . Proper layouts and live-reloads came later, the whole blog has been a
single Haskell file until long (i.e., when compilation time where too long
while changing only the layout).
This section does not speak about Haskell but rather focuses on the general architecture. Thus when I say “a function” you can imagine it’s “a monad” if you feel compelled to entertain an annoying cliché about Haskellers detached from reality.
Main Architectural Blocks
The following picture sketches roughly the blog engine pipeline.
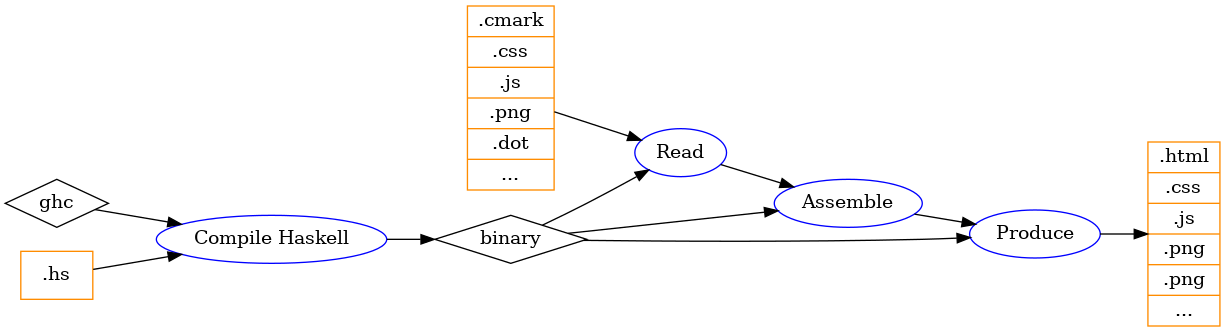
- compile
ghcturns Haskell code into abinarythat contains the blog layout and advanced rules - read collects all input files, possibly other sources
- assemble builds an understanding of everything that needs to be generated, copied etc.
- produce writes all the needed files to the right location
So overall it is pretty simple and nothing is ground-breaking. Assuming the
compile step is already done you have a binary. The binary will have a fixed
layout that can generate a blog for new content. To illustrate, adding a new
article is done by adding a new .cmark file but requires no recompilation. But
changing the HTML structure to display the social links requires a
code-change and a recompilation.
To motivate the next sections it is worth detailing the assembly-part of the
blog engine. Let’s focus on read -> assemble -> produce steps.
detailed assembly pipeline
A more detailed conceptual pipeline of the three last steps is as follows. In the following graph arrows represent the data flow (i.e., starting from inputs data representations progress towards the output files).
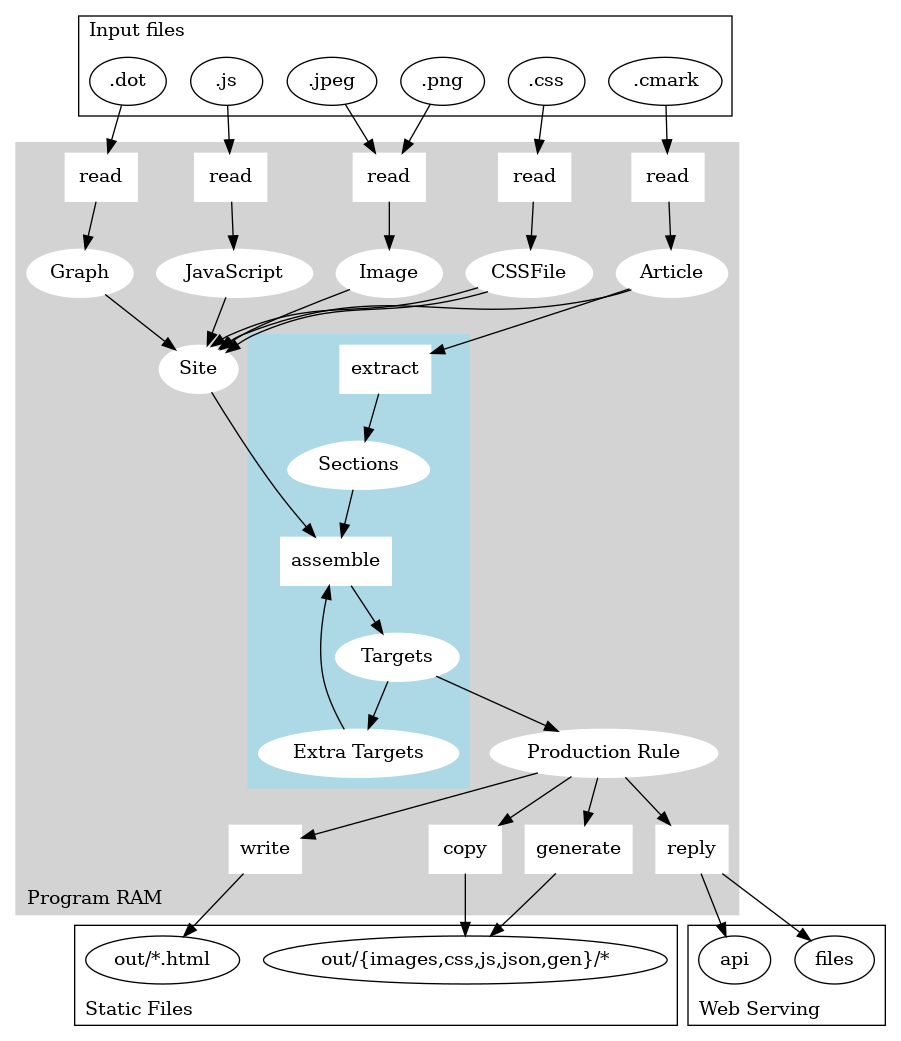
At the top you get input files such as CSS or Commonmark files. We could easily
add external inputs as well. All these sources get stuffed into an object named
Site which sort of contains the whole knowledge about inputs for a Site.
An assemble function then takes the Site and turns that into Targets
objects. The Targets themselves are not yet concrete files. Rather, they are
annotated recipes about how to produce a single output. The recipe itself is
named a Production Rule.
The Production Rules then can be executed on demand to either generate static
files or being generated on the fly by a web-server (if the web-server is
written in Haskell). We are lucky enough to have very good web-servers and
web-API libraries in Haskell which allows to compose such an hybrid system –
this hybrid system is handy for the developer-mode.
A key aspect of the pipeline (highlighted in the picture) is that the assemble function actually is a bit more complicated than a mere mapping from JS, Markdown etc. There are two complications:
- Extra-Targets can be computed from main targets, for instance each topic gets a listing page. These rules mainly are written in Haskell: the
index.cmarkalso needs the list of allArticletargets to generate extra content on top of some text written in Commonmark; for eachtagwe create an index Target page and they all use the sametags.cmarkinstructions Articlesare written in Commonmark however the blog engine expects a special format that containsSections, these Sections contain the meaty content but also metadata information in JSON and commands that could lead to generating more files
Overall, I need to use an ad-hoc mix of Haskell and Commonmark to generate pages and their templates. This mix is means there sometimes is two ways to do a thing (e.g., should I add some default CSS file in the layout or via includes in the CSS-section of individual articles so that I can override it entirely?) with no clear immediate tradeoff.
sample output
When the binary executes you get an uninteresting log of what occurs. This log can help understand what happens.
found site-src/talks.md
found site-src/how-this-blog-works.md
found site-src/snake-cube.md
found site-src/alphabets.md
found site-src/tags.md
found site-src/santa-wrap.md
found site-src/about-me.md
found site-src/index.md
generating out/gen/out/index.md__gen-date.txt
executing `date` with args []
generating out/gen/out/index.md__gen-git-head-sha.txt
executing `git` with args ["rev-parse","HEAD"]
assembling out/talks.html
assembling out/how-this-blog-works.html
assembling out/snake-cube.html
assembling out/alphabets.html
assembling out/santa-wrap.html
assembling out/about-me.html
assembling out/index.html
copying out/images/snake-cube-folded.jpeg
copying out/images/snake-cube-l-shape.png
copying out/images/snake-cube-mzn-003.png
copying out/images/snake-cube-coords.png
copying out/images/snake-cube-mzn-001.png
copying out/images/sword.png
copying out/images/layout-restricted.png
copying out/images/geost-doc.png
copying out/images/parts.png
copying out/images/background.png
copying out/images/snake-cube-mzn-002.png
copying out/images/layout-robot-200x240.png
copying out/images/deps.png
copying out/images/layout-190x150.png
copying out/images/layout-190x160.png
copying out/images/haddock-jp.png
copying out/images/snake-cube-unfolded.jpeg
copying out/images/linear-layout.png
generating out/gen/images/blog-phases.dot.png
executing `dot` with args ["-Tpng","-o","/dev/stdout","site-src/blog-phases.dot"]
generating out/gen/images/blog-engine.dot.png
executing `dot` with args ["-Tpng","-o","/dev/stdout","site-src/blog-engine.dot"]
copying out/css/index-wide.css
copying out/css/index-narrow.css
copying out/css/main.css
copying out/js/autoreload.js
assembling out/topics/about-me.html
assembling out/topics/constraint-programming.html
assembling out/topics/formal-methods.html
assembling out/topics/fun.html
assembling out/topics/haskell.html
assembling out/topics/minizinc.html
assembling out/topics/optimization.html
assembling out/topics/sre.html
assembling out/topics/web.html
generating out/json/paths.json
generating out/json/filecounts.json
(this excerpt is out of date but not you get the boring feeling)
Section-based file format
An input file for an Article is suffixed .cmark.
The content of a single file with multiple sections is a file like the following example:
=base:build-info.json
{"layout":"article"
}
=base:preamble.json
{"author": "Lucas DiCioccio"
,"date": "2022-02-01T12:00:00Z"
,"title": "An article about Haskell"
}
=base:topic.json
{"topics":["haskell", "some-tag"]
,"keywords":["some keyword"]
}
=base:social.json
{"twitter": "me"
,"linkedin": "myself"
,"github": "again-me"
}
=base:summary.cmark
Some summary.
=base:main-content.cmark
# this is an h1 title
## this is an h2 title
lorem ipsum ...
=base:main-css.css
@import "/css/main.css"
Each section is a textual block starting with a special delimiter like
=base:build-info.json. The layout code actually interprets these sections
and look for various information. For instance, the =base:topic.json contains
information to add some topic-index and meta tags. The =base:main-css.css
section allows to write some CSS that will be inlined in the HTML (conversely,
.css files found in the source directory will be copied around).
These sections could all be collapsed in a single section however I find it convenient to have one small datatype per logical ‘metadata’ piece.
Dev-mode and auto-reload
The dev-server API itself is written with my prodapi API library, which curates some good Haskell libraries for building APIs. There is enough to help running background tasks in the process (e.g., to watch for file-changes), and also to expose other dev-mode-only endpoints.
Examples of dev-mode-only endpoints are:
- a listing of all targets (which is useful when I lose track of what targets exist)
- an endpoint I can call to rebuild the static-file outputs from the dev-server directly (rather than running the binary with different parameters)
- build-time statistics
- autoreload-helpers (see the dedicated section below)
autoreload
I have a poor-man’s autoreload.js script (source here source of auto-reload
script). That perform long-polling to a API route
/dev/watch that only the dev-webserver knows about (i.e., there won’t be a
Target to generate for this URL path). The autoreload.js script performs a
full-page reload, which is acceptable as most of the articles I will ever write
will mostly be stateless texts but.
The current implementation works using the amazing Software Transactional Memory (STM) support in Haskell and supports live-reloading mutliple pages simultaneously from different clients connected to a same server (not like I really use this feature but it does not incur much more work). Implementation of the live-reload is illustrated as follows:
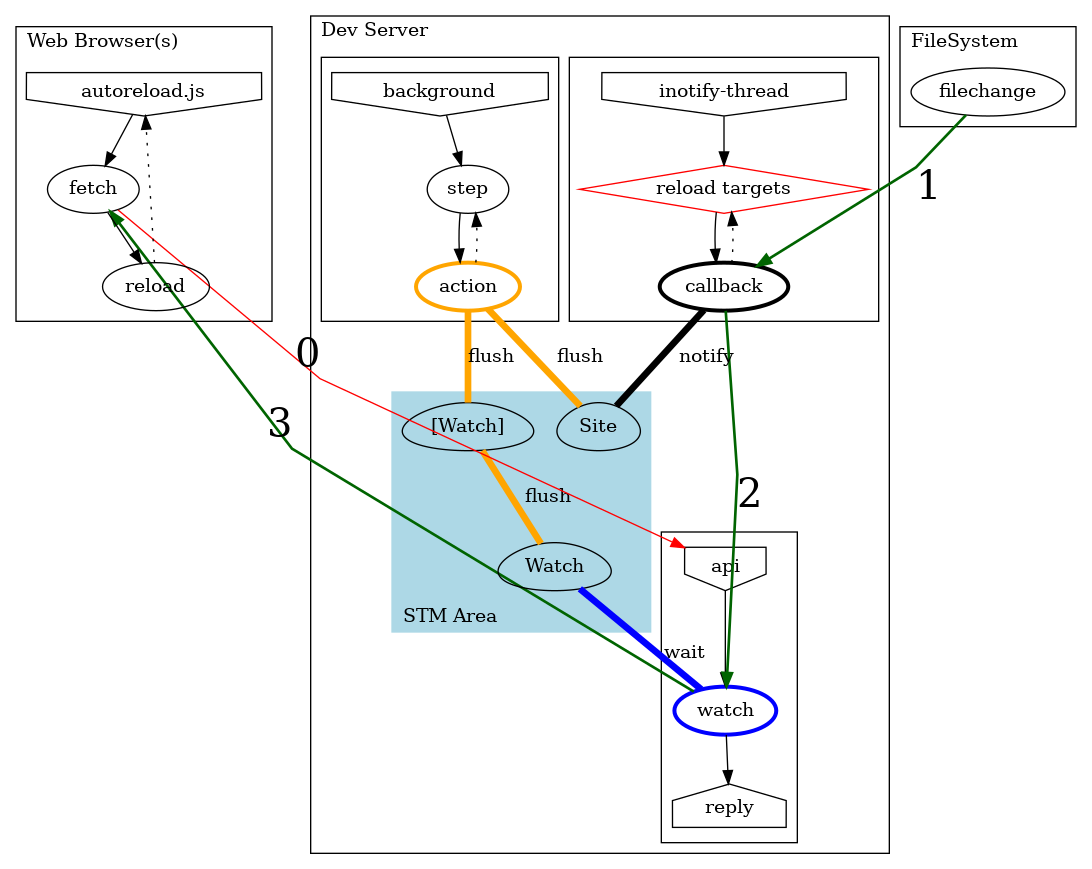
The server API route mediates a rendez-vous between:
- The
Web Browserwho waits for an answer to the API call Filesystemchanges that are propagated via inotify
Overall, from a high-level perspective the live-reload follows these four simple steps:
- Step-0. after loading the
.jsa browser starts a watch over the HTTP request API handler - Step-1. inotify notifies the file-system change
- Step-2. the watch terminates
- Step-3. the HTTP request finishes, the browser reloads (which will return to Step-0)
Three threads co-exist in the server:
- the
inotifycallbacks loads targets then propagates them in a Site (using aTMVar Site), this thread is like if an event-stream of updated Sites was available but we only hold-on to the latest value - the
apiregisters a Watch (using oneTMVar ()per HTTP-request) and inserts it in a list of pending watchers [Watch] , then waits for the Watch to end - the server
backgroundwaits for the filesystem flag changes, clears the flag, then fans-out the signal to waiting HTTP-clients, all of this is atomic outside the STM area (all the changeds are annotatedflushin orange on the picture)
Experience report
It has been fun to write some get-stuff-done Haskell. I sincerely believe this blog engine does not have to shy away in face of other tools. I will surely try to extract the library code as a standalone engine at some point, but for now my repository mixes library, specific layout and rules for my own blog, and content.
Let me explain a few things that I find rather pleasant.
Sections and file generators
Some interesting Sections and ProductionRules:
- dotfile conversion: turn a
.dotfile into a.pngwith GraphViz; the live-reload in the output web-page without leavingvimmakes it a breeze (see video below) - section command-gen: generates a file from a UNIX command (e.g., to get a special file with the git-sha or build timestamp)
- section summary: short Commonmark content that appear in article listings (it also gets stripped down to text to add a meta tag)
- section taken-off: stuff that is in the source but will be ignored, useful for draft sections
The following video gives an idea of how the live-reload of GraphViz-generated images work:
I find this live-reload good enough to now run my blog-engine when I need to quickly edit such a graph for work.
Commonmark is great
The Commonmark package supports extensions.
For instance, I have enabled the emoji syntaxt that turns :smiley: into
😃. I also enabled support for directly adding HTML tags (including JS)
or annotating sections of code with HTML attributes if the rendering is not
sufficient. Another use case is when you want to drop down to HTML or if you
need small-scripting capabilities.
With HTML-tagging and JS inclusion, the following code:
::: {.example}
press to get an alert
<button class="example-button" onClick="alert('hi from commonmark')">press me</button>
:::
… gives the following rendering (with some CSS style defined in the CSS-section).
press to get an alert
You can get creative
Direct-embedding of JavaScript allows me to write JavaScript as page-enhancement snippets (e.g., adding a ‘mail-to’ tag for each talk in the Talks page). What excites me the most is that I can also build some full-blown visualizations (e.g., the graph-view on the home page). The Haskell-side of the blog-engine allows me to implement pretty much arbitrary logic to prepare some JSONs objects as special targets. Such objects typically are article-specific or site-wide summaries. I can then treat these targets as API endpoints that have fixed content once the site is entirely-produced but where the data is dynamically-recomputed while in developer mode.
site-wide statistics
An example of this JavaScript usage below shows you can embed JavaScript for visualizations (example with Vega-Lite). Further, the visualization loads a special file json-file-counts that has been generated as a special Target part of the layout. However, a generator section could also create a similar target.
article-shape statistics
I typically try to balance-out my articles. While writing LaTex, it’s easy to see the page/column count per page. In HTML we do not really have an immediate equivalent.
A good example of per-article statistics is a histogram made with Apache ECharts that I produce and display while in developer-mode to get a visual glimpse of how the article is shaped.
On the X-axis you get an index of text blocks in the Commonmark file. Whereas
the Y-axis is the cumulative number of words so far. This way I can visualize
what is the shape of the article and detect highly-imbalanced paragraphs. This
histogram is “work in progress” and I tend to adapt it when I feel like it
(I would like to also have markers for images/links). This visualization is
automatically-inserted in the “developer mode” layout. However, given that the
JSON object target with the article stats is a generated
target, I can show you in this article
by manually inserting the JavaScript. The JavaScript
code knows the URL to the special target for the current article with
statistics by looking up a custom <meta> tag, so that the JavaScript include
does not require tweaking or per-page configuration. Longer term, I may
decorate every article with such a navigation help.
Future ideas
Besides open-sourcing the engine (which means tracking hardcoded things or personal-layouts, plus maintaining an external project). There is much I would like to implement. Unfortunately, these ideas have an activation function a bit higher than I have energy these days. More bluntly, I’d rather focus on writing more content rather than working on the blog engine itself.
Regarding templating. I still would like some interpreted templating (e.g.,
Mustache) for some very specific cases such as data tables, with data generated
from another section. The reason is that to add a new article I should write
code only for the article rather than splitting haskell and Commonmark around
(exceptions are special pages like tags.md and index.md).
This will require some extra wiring in the Target-assembly part and some difficult decision as to what is really-static and what is in-fact dynamic. My main inspiration are Jupyter notebooks.
Regarding new sections, targets, or layouts. I would like to allow to have
scripting-language sections (for now I only have direct shell commands). For
instance to generate a picture using R or Python. It would be nice as well
to inline the dot-source of GraphViz pictures directly in the .cmark file.
RSS targets also are on my wishlist, however I do not use a lot of RSS myself.
I also would like to have some article-type layouts for photo albums and
snippet-like entries (e.g. to improve on the Tips page).
Regarding dependency-graphs. I would like to have a section where required URLs can be declared. Doing so will enable more interesting build sequences.
As a fluid static to web-app engine, I think this blog-engine is a good starting-point for mixed website where some pages or endpoint are dynamic API calls. I already have a “serve mode” for the day where I feel compelled to move out of GitHub pages. The “serve-mode” for now is just the “dev mode” but without the special-routes and special-layouts but it would need some extra configurations and simple caching strategies to reduce security-risk vectors (e.g., to prevent arbitrary-commands generators and costly targets to be run on demand).
Some inspiration for future work can also be found in the Readings page (section “Static and personal site technology).